This is part two of the ‘applied statistical theory’ series that will cover the bare essentials of various statistical techniques. As analysts, we need to know enough about what we’re doing to be dangerous and explain approaches to others. It’s not enough to say “I used X because the misclassification rate was low.”
Standard linear regression summarizes the average relationship between a set of predictors and the response variable. 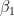 represents the change in the mean value of
represents the change in the mean value of 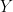 given a one unit change in
given a one unit change in 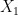 . A single slope is used to describe the relationship. Therefore, linear regression only provides a partial view of the link between the response variable and predictors. This is often inadaquete when there is heterogenous variance between
. A single slope is used to describe the relationship. Therefore, linear regression only provides a partial view of the link between the response variable and predictors. This is often inadaquete when there is heterogenous variance between 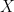 and . In such cases, we need to examine how the relationship between and changes depending on the value of . For example, the impact of education on income may be more pronounced for those at higher income levels than those at lower income levels. Likewise, the the affect of parental care on the mean infant birth weight can be compared to it’s effect on other quantiles of infant birth weight. Quantile regression solves for these problems by looking at changes in the different quantiles of the response. The parameter estimates for this technique represent the change in a specified quantile of the response variable produced by a one unit change in the predictor variable. One major benefit of quantile regression is that it makes no assumptions about the error distribution.
and . In such cases, we need to examine how the relationship between and changes depending on the value of . For example, the impact of education on income may be more pronounced for those at higher income levels than those at lower income levels. Likewise, the the affect of parental care on the mean infant birth weight can be compared to it’s effect on other quantiles of infant birth weight. Quantile regression solves for these problems by looking at changes in the different quantiles of the response. The parameter estimates for this technique represent the change in a specified quantile of the response variable produced by a one unit change in the predictor variable. One major benefit of quantile regression is that it makes no assumptions about the error distribution.
library(quantreg)
head(mtcars)
frmla <- mpg ~ .
u=seq(.02,.98,by=.02)
mm = rq(frmla, data=mtcars, tau=u) # for a series of quantiles
mm = rq(frmla, data=mtcars, tau=0.50) # for the median
summ <- summary(mm, se = "boot")
summ
plot(summ)
