A. INTRODUCTION
When building statistical models, the goal is to define a compact and parsimonious mathematical representation of some data generating process. Many of these techniques require that one make assumptions about the data or how the analysis is specified. For example, Auto Regressive Integrated Moving Average (ARIMA) models require that the time series is weakly stationary or can be made so. Furthermore, ARIMA assumes that the data has no deterministic time trends, the variance of the error term is constant, and so forth. Assumptions are generally a good thing, but there are definitely situations in which one wants to free themselves from such “constraints.”
In the context of evaluating relationships between one or more target variables and a set of explanatory variables, semiparametric regression is one such technique that provides the user with some flexibility in modeling complex data without maintaining stringent assumptions. With semiparametric regression, the goal is to develop a properly specified model that integrates the simplicity of parametric estimation with the flexibility provided by nonparametric splines.
B. LINEAR REGRESSION
A core requirement of both linear and generalized linear regression is that the user must define a set of explanatory variables and functional form that describes the relationship between the predictors and response variable. So when the goal is to build a linear regression model that explains which social and political characteristics within a country account for different levels of macroeconomic performance, we must first specify a number of variables that may explain our target variable. Furthermore, we must specify the functional form of the relationship. In both linear and generalized linear regression, this refers to how we characterize and “encode” each of the explanatory variables. So if we include the log of yearly precipitation rate as
a predictor such that 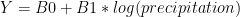

C. REGRESSION SPLINES
One way to ensure that the model is properly specified is through the use of nonparametric splines. Instead of assuming that we know the functional form for a regression model, the user would essentially estimate the appropriate functional form from the data. Compared to a traditional parametric model whereby we estimate one global value that represents the relationship between 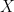
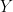
In our previous model where the goal was to identify how macroeconomic performance is affected by weather/precipitation, the linear regression model would look like 

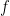
Before we look at how to implement semiparametric regression, it is worth noting that these types of models are often referred to as either general or generalized additive models. Furthermore, semiparametric variations of other regression models are available such as semiparametric quantile regression and even semiparametric nonlinear regression.
D. R EXAMPLE
For this post, I’m going to stick with the gam function in the mgcv package because it is usually a good starting point. Taking the previous use case, let’s create some data and construct a linear regression model that regresses economy as a function of weather. Given that the data is from a random distribution, we obviously find a weak relationship between the two variables.
mydat = data.frame(economy = rnorm(100), weather = rnorm(100)) mod = lm(economy ~ weather, data=mydat) summary(mod) plot(economy ~ weather, data = mydat, cex = .8) abline(mod, col="red")
Let us say that we know based on experience, theory, or other sources that linearity in the variables is a poor specification in this domain case. One thing that could be done is to incorporate a spline to create local estimates for our explanatory variable within the linear regression.
mod <- lm(economy ~ bs(weather, knots = 3), data=mydat) summary(mod) plot(economy ~ weather, data = mydat, cex = .8) lines(mydat$weather, predict(mod), lwd=2, col='red')
The same model could also be examined using gam. Take note of the edf value, which represents how much the explanatory variable is smoothed.
library(mgcv) mod <- gam(economy ~ s(weather, bs = "cr", k = 3), data = mydat, family = gaussian) summary(mod) plot(mod)
This example data is pretty silly, but this should give you some things to investigate in terms of learning how semiparametric models can help improve the inferences that you are examining.
Have questions, comments, interesting work, etc? Feel free to contact me at [email protected]
Up next will be a series of posts on causal inference, a topic that I’ve been trying to get a better understanding of over the past month.
