Let’s face it, a good statistics refresher is always worthwhile. There are times we all forget basic concepts and calculations. Therefore, I put together a document that could act as a statistics refresher and thought that I’d share it with the world. This is part one of a two part document that is still being completed. This refresher is based on Principles of Statistics by Balmer and Statistics in Plain English by Brightman.
The Two Concepts of Probability
Statistical Probability
- Statistical probability pertains to the relative frequency with which an event occurs in the long run.
- Example:
Let’s say we flip a coin twice. What is the probability of getting two heads?
If we flip a coin twice, there are four possible outcomes,.
Therefore, the probability of flipping two heads is

Inductive Probability
- Inductive probability pertains to the degree of belief which is reasonable to place on a proposition given evidence.
- Example:
I’mcertain that the answer to
is between
and
.
The Two Laws of Probability
Law of Addition
- If
and
are mutually exclusive events, the probability that either
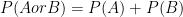
Law of Multiplication
- If
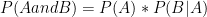
Conditional Probability
- The probability of
, is the probability that
.
Random Variables and Probability Distributions
Discrete Variables
- Variables which arise from counting and can only take integral values
.
- A frequency distribution represents the amount of occurences for all the possible values of a variable. This can be represented in a table or graphically as a probability distribution.
- Associated with any discrete random variable,
, is a corresponding probability function which tells us the probability with which
. Based on
.
- The cumulative probability function specifies the probability that
. The cumulative probability function can be calculated by summing the probabilities of all values less than or equal to
![F(x) = Prob[X \leq x]](https://s0.wp.com/latex.php?latex=F%28x%29+%3D+Prob%5BX+%5Cleq+x%5D+&bg=%23ffffff&fg=%23000000&s=0&c=20201002)

Continuous Variables
- Variables which arise from measuring and can take any value within a given range.
- Continuous variables are best graphically represented by a histogram, where the area of each rectangle represents the proportion of observations falling in that interval.
- The probability density function,
, refers to the smooth continuous curve that is used to describe the relative likelihood a random variable to take on a given value.
and
.
- A continuous probability distribution can also be represented by its cumulative probability function,
- A continuous random variable is said to be uniformly distributed between
and
if it is equally likely to lie anywhere in this interval but cannot lie outside it.
Multivariate Distributions
- The joint frequency distribution of two random variables is called a bivariate distribution.
denotes the probability that simultaneously
will be
. This is expressed through a bivariate distribution table.
![P(x,y) = Prob[X == x \space and \space Y == y]](https://s0.wp.com/latex.php?latex=P%28x%2Cy%29+%3D+Prob%5BX+%3D%3D+x+%5Cspace+and+%5Cspace+Y+%3D%3D+y%5D+&bg=%23ffffff&fg=%23000000&s=0&c=20201002)
- In a bivariate distribution table, the right hand margin sums the probabilities in different rows. It expresses the overall probability distribution of
![p(x) = Prob[X == x] = \sum_{y} p(x,y)](https://s0.wp.com/latex.php?latex=p%28x%29+%3D+Prob%5BX+%3D%3D+x%5D+%3D+%5Csum_%7By%7D+p%28x%2Cy%29+&bg=%23ffffff&fg=%23000000&s=0&c=20201002)
- In a bivariate distribution table, the bottom margin sums the probabilities in different columns. It expresses the overall probability distribution of
![p(y) = Prob[Y == y] = \sum_{x} p(x,y)](https://s0.wp.com/latex.php?latex=p%28y%29+%3D+Prob%5BY+%3D%3D+y%5D+%3D+%5Csum_%7Bx%7D+p%28x%2Cy%29+&bg=%23ffffff&fg=%23000000&s=0&c=20201002)
Properties of Distributions
Measures of Central Tendancy
- The mean is measured by taking the sum divided by the number of observations.
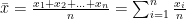
- The median is the middle observation in a series of numbers. If the number of observations are even, then the two middle observations would be divided by two.
- The mode refers to the most frequent observation.
- The main question of interest is whether the sample mean, median, or mode provides the most accurate estimate of central tendancy within the population.
Measures of Dispersion
- The standard deviation of a set of observations is the square root of the average of the squared deviations from the mean. The squared deviations from the mean is called the variance.
The Shape of Distributions
- Unimodal distributions have only one peak while multimodal distributions have several peaks.
- An observation that is skewed to the right contains a few large values which results in a long tail towards the right hand side of the chart.
- An observation that is skewed to the left contains a few small values which results in a long tail towards the left hand side of the chart.
- The kurtosis of a distribution refers to the degree of peakedness of a distribution.
The Binomial, Poisson, and Exponential Distributions
Binomial Distribution
- Think of a repeated process with two possible outcome, failure (
) and success (
). After repeating the experiment
times, we will have a sequence of outcomes that include both failures and successes,
. The primary metric of interest is the total number of successes.
- What is the probability of obtaining
failures in
Poisson Distribution
- The poisson distribution is the limiting form of the binomial distribution when there are a large number of trials but only a small probability of success at each of them.
Exponential Distribution
- A continuous, positive random variable is said to follow an exponential distribution if its probability density function decreases as the values of
. The probability declines from its highest levels at the initial values of
The Normal Distribution
Properties of the Normal Distribution
- The real reason for the importance of the normal distribution lies in the central limit theorem, which states that the sum of a large number of independent random variables will be approximately normally distributed regardless of their individual distributions.
- A normal distribution is defined by its mean,
, and standard deviation,
. A change in the mean shifts the distribution along the x-axis. A change in the standard deviation flattens it or compresses it while leaving its centre in the same position. The totral area under the curve is one and the mean is at the middle and divides the area into halves.
- One standard deviation above and below the mean of a normal distribution will include 68% of the observations for that variable. For two standard deviates, that value will be 95%, and for three standard deviations, that value will be 99%.
There you have it, a quick review of basic concepts in statistics and probability. Please leave comments or suggestions below. If you’re looking to hire a marketing scientist, please contact me at [email protected]
