As data analysts, we’re frequently presented with comma-separated value files and tasked with reporting insights. While it’s tempting to import that data directly into R or Python in order to perform data munging and exploratory data analysis, there are also a number of utilities to examine, fix, slice, transform, and summarize data through the command line. In particular, Csvkit is a suite of python based utilities for working with CSV files from the terminal. For this post, we will grab data using wget, subset rows containing a particular value, and summarize the data in different ways. The goal is to take data on criminal activity, group by a particular offense type, and develop counts to understand the frequency distribution.
Lets start by installing csvkit. Go to your command line and type in the following commands.
$ pip install csvkit
One: Set the working directory.
$ cd /home/abraham/Blog/Chicago_Analysis
Two: Use the wget command to grab data and export it as a csv file entitled rows.
$ wget –no-check-certificate –progress=dot https://data.cityofchicago.org/api/views/ijzp-q8t2/rows.csv?accessType=DOWNLOAD > rows.csv
This dataset contains information on reported incidents of crime that occured in the city of Chicago from 2001 to present. Data comes from the Chicago Police Department’s Citizen Law Enforcement Analysis and Reporting system.
Three: Let’s check to see which files are now in the working directory and how many rows that file contains. We will also use the csvcut command to identify the names of each column within that file.
$ ls
$ wc -l rows.csv
$ csvcut -n rows.csv
Four: Using csvsql, let’s find what unique values are in the sixth column of the file, primary type. Since we’re interested in incidents of prostitution, those observations will be subset using the csvgrep command, and transfered into a csv file entitled rows_pros.
$ csvsql –query “SELECT [Primary Type], COUNT(*) FROM rows GROUP BY [Primary Type]” rows.csv | csvlook
$ csvgrep -c 6 -m PROSTITUTION rows.csv > rows_pros.csv
Five: Use csvlook and head to have a look at the first few rows of the new csv file. The ‘Primary Type’ should only contain information on incidents of crime that involved prostitution.
$ wc -l rows_pros.csv
$ csvlook rows_pros.csv | head
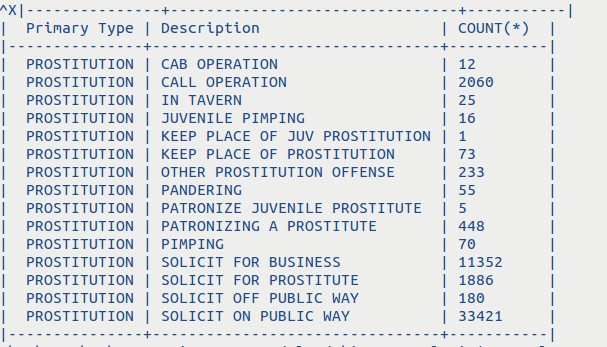
Six: We’ve now got the data we need. So let’s do a quick count of each description that is associated with the prostitution offense. This is done using the csvsql and csvlook command line tools.
$ csvsql –query “SELECT [Primary Type], Description, COUNT(*) FROM rows_pros GROUP BY Description” rows_pros.csv | csvlook
This has been a quick example of how the various csvkit utilities can be used to take a large csv file, extract specific observations, and generate summary statistics by executing a SQL query on that data. While this same analysis could have been performed in R or Python in a more efficient manner, it’s important for analysts to remember that the command line offers a variety of important utilities that can simplify their daily job responsibilities.
