For this final post, I will cover some advanced topics and discuss how to use data tables within user generated functions. Once again, let’s use the Chicago crime data.
dat = fread("rows.csv")
names(dat) <- gsub(" ", "_", names(dat))
dat[, c("value1", "value2", "value3") := sample(1:50, nrow(dat), replace=TRUE)]
dat[1:3]
Let’s start by subseting the data. The following code takes the first 50000 rows within the dat dataset, selects four columns, creates three new columns pertaining to the data, and then removes the original date column. The output was saved as to new variable and the user can see the first few columns of the new data table using brackets or head function.
ddat = dat[1:50000, .(Date, value1, value2, value3)][,
c("year", "month", "day") :=
.(year(mdy_hms(Date)),
month(mdy_hms(Date)),
day(mdy_hms(Date)))][,-c("Date")]
ddat[1:3] # same as head(ddat, 3)
We can now do some intermediate calculations and suppress their output by using braces.
unique(ddat$month)
ddat[, { avg_val1 = mean(value1)
new_val1 = mean(abs(value2-avg_val1))
new_val2 = new_val1^2 }, by=month][order(month)]
In this simple sample case, we have taken the mean value1 for each month, subtracted it from value2, and then squared that result. The output show the final calculation in the brackets, which is the result from squaring. Note that I also ordered the results by month with the chaining process.
That’s all very nice and convenient, but what if we want to create user defined functions that essentially automate these tasks for future work. Let us start with a function for extracting each component from the date column.
ddat = dat[1:50000, .(Date, value1, value2, value3)]
add_engineered_dates <- function(mydt, date_col="Date"){
new_dt = copy(mydt)
new_dt[, paste0(date_col, "_year") := year(mdy_hms(get(date_col)))]
new_dt[, paste0(date_col, "_month") := month(mdy_hms(get(date_col)))]
new_dt[, paste0(date_col, "_day") := day(mdy_hms(get(date_col)))]
new_dt[, c(date_col) := NULL]
new_dt[]
}
We’ve created a new functions that takes two arguments, the data table variable name and the name of the column containing the date values. The first step is to copy the data table so that we are not directly making changes to the original data. Because the goal is to add three new columns that extract the year, month, and day, from the date column, we’ve used the lubridate package to define the date column and then extract the desired values. Furthermore, each new column has been labeled so that it distinctly represents the original date column name and the component that it contains. The final step was to remove the original date column, so we’ve set the date column to NULL. The final line prints the results back to the screen. You can recognize from the code above that the get function is used to take a variable name that represents column names and extract those columns within the function.
result = add_engineered_dates(ddat) result
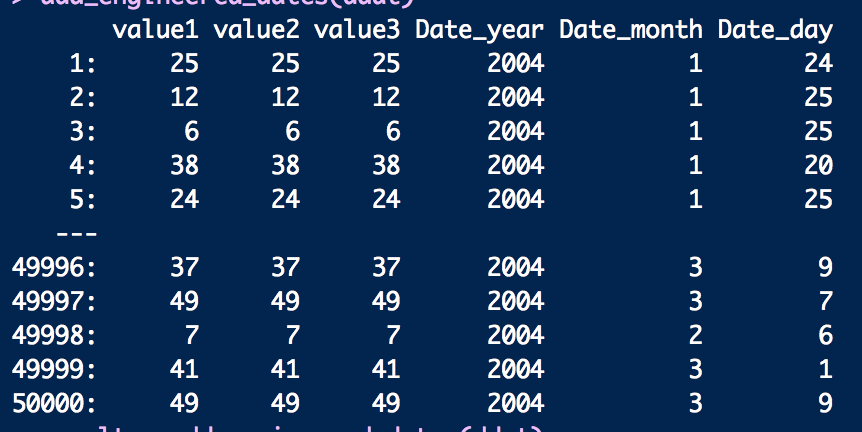
Let’s now apply the previous code with braces to find the squared difference between value2 and the mean value1 metric.
result[, { avg_val1 = mean(value1)
new_val1 = mean(abs(value2-avg_val1))
new_val2 = new_val1^2 }, by=.(Date_year,Date_month)][
order(Date_year,Date_month)][1:12]
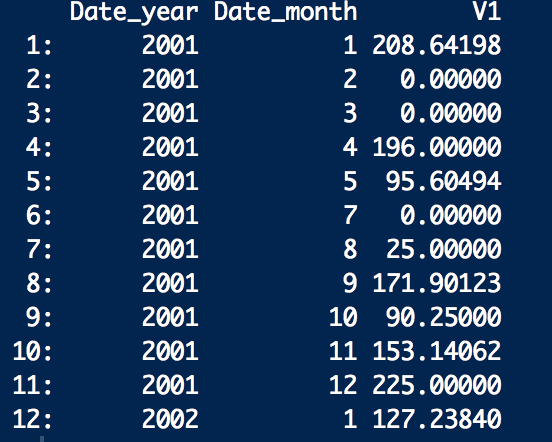
Perfect!
I’m hoping that these three posts have convinced beginners to the R language that the data.table package is beautiful and worth checking out. The syntax may be scary at first, but it offers an array of powerful tools that everyone should become familiar with. So pull your sleeves up and have fun.
If you have any comments or would like to cover other specific topics, feel free to comment below. You can also contact me at [email protected] or reach me through LinkedIn
