Applied statistical theory is a new series that will cover the basic methodology and framework behind various statistical procedures. As analysts, we need to know enough about what we’re doing to be dangerous and explain approaches to others. It’s not enough to say “I used X because the misclassification rate was low.” At the same time, we don’t need to have doctoral level understanding of approach X. I’m hoping that these posts will provide a simple, succinct middle ground for understanding various statistical techniques.
Probabilistic grphical models represent the conditional dependencies between random variables through a graph structure. Nodes correspond to random variables and edges represent statistical dependencies between the variables. Two variables are said to be conditionally dependent if they have a direct impact on each others’ values. Therefore, a graph with directed edges from parent 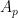
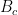
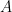
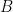

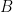

Let’s consider a graphical model with 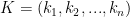
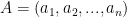
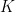
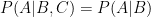
There you go; the absolute basics. And below is a presentation on belief networks that I made last year.

