My previous post covered the basics of logistic regression. We must now examine the model to understand how well it fits the data and generalizes to other observations. The evaluation process involves the assessment of three distinct areas – goodness of fit, tests of individual predictors, and validation of predicted values – in order to produce the most useful model. While the following content isn’t exhaustive, it should provide a compact ‘cheat sheet’ and guide for the modeling process.
Goodness of Fit: Likelihood Ratio Test
A logistic regression is said to provide a better fit to the data if it demonstrates an improvement over a model with fewer predictors. This occurs by comparing the likelihood of the data under the full model against the likelihood of the data under a model with fewer predictors. The null hypothesis, 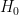
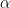
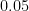
Goodness of Fit: Pseudo
With linear regression, the 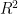
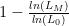
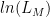
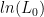

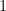

Goodness of Fit: Hosmer-Lemeshow Test
The Hosmer-Lemeshow test examines whether the observed proportion of events are similar to the predicted probabilities of occurences in subgroups of the dataset using a pearson chi-square statistic from the 2 x g table of observed and expected frequencies. Small values with large p-values indicate a good fit to the data while large values with p-values below
Tests of Individual Predictors: Wald Test
A wald test is used to evaluate the statistical significance of each coefficient in the model and is calculated by taking the ratio of the square of the regression coefficient to the square of the standard error of the coefficient. The idea is to test the hypothesis that the coefficient of an independent variable in the model is not significantly different from zero. If the test fails to reject the null hypothesis, this suggests that removing the variable from the model will not substantially harm the fit of that model.
Tests of Individual Predictors: Variable Importance
To assess the relative importance of individual predictors in the model, we can also look at the absolute value of the t-statistic for each model parameter. This technique is utilized by the varImp function in the caret package for general and generalized linear models. The t-statistic for each model parameter helps us determine if it’s significantly different from zero.
Validation of Predicted Values: Classification Rate
With predictive models, he most critical metric regards how well the model does in predicting the target variable on out of sample observations. The process involves using the model estimates to predict values on the training set. Afterwards, we will compare the predicted target variable versus the observed values for each observation.
Validation of Predicted Values: ROC Curve
The receiving operating characteristic is a measure of classifier performance. It’s based on the proportion of positive data points that are correctly considered as positive, 
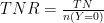


library(pROC) # Compute AUC for predicting Class with the variable CreditHistory.Critical f1 = roc(Class ~ CreditHistory.Critical, data=training) plot(f1, col="red") library(ROCR) # Compute AUC for predicting Class with the model prob <- predict(mod_fit_one, newdata=testing, type="response") pred <- prediction(prob, testing$Class) perf <- performance(pred, measure = "tpr", x.measure = "fpr") plot(perf) auc <- performance(pred, measure = "auc") auc <- [email protected][[1]] auc
This post has provided a quick overview of how to evaluate logistic regression models in R. If you have any comments or corrections, please comment below.
