Logistic regression is used to analyze the relationship between a dichotomous dependent variable and one or more categorical or continuous independent variables. It specifies the likelihood of the response variable as a function of various predictors. The model expressed as 
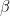
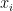

![ln[\frac{p}{1-p}]](https://s0.wp.com/latex.php?latex=ln%5B%5Cfrac%7Bp%7D%7B1-p%7D%5D&bg=%23ffffff&fg=%23000000&s=0&c=20201002)
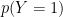

The models estimates, 

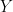
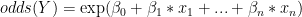
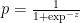
Using the GermanCredit dataset in the Caret package, we will construct a logistic regression model to estimate the likelihood of a consumer being a good loan applicant based on a number of predictor variables.
library(caret) data(GermanCredit) # split the data into training and testing datasets Train <- createDataPartition(GermanCredit$Class, p=0.6, list=FALSE) training <- GermanCredit[ Train, ] testing <- GermanCredit[ -Train, ] # use glm to train the model on the training dataset. make sure to set family to "binomial" mod_fit_one <- glm(Class ~ Age + ForeignWorker + Property.RealEstate + Housing.Own + CreditHistory.Critical, data=training, family="binomial") summary(mod_fit_one) # estimates exp(coef(mod_fit_one)) # odds ratios predict(mod_fit_one, newdata=testing, type="response") # predicted probabilities
Great, we’re all done, right? Not just yet. There are some critical questions that still remain. Is the model any good? How well does the model fit the data? Which predictors are most important? Are the predictions accurate? In the next post, I’ll provide an overview of how to evaluate logistic regression models in R.
